
Cameron Riopelle
- Director of Research Data & Open Scholarship
- criopelle@miami.edu
- (305) 284-1524

Thilani Samarakoon
- Biomedical Data Librarian
- thilani.samarakoon@miami.edu
- (305) 243-9126

Timothy Norris
- Data Scientist
- tnorris@miami.edu
- (305) 284-2826
Data Publication
DOIs, Data Publication, Sharing and Preservation Sensitive Data and Privacy Concerns FAIR DataDOI Services
DOI Services What is a DOI? DOI Minting GuidelinesData Repositories
Data Repositories The University of Miami Scholarly RepositoryData Licensing
Data Licensing Open DataData Publication Checklist
Data Publication Checklist Creating a Data PackageWhy publish or share data?
Publication of data as a supplement to journal article publications or as a stand alone data publications is increasingly recognized as good scholarship within many disciplines. Your work becomes more visible, has more impact, and is more likely to be preserved for the future.
Additionally many funding agencies and journal publishers now have data sharing requirements.
What are the options to share or publish data?
There are many forms of publishing or sharing data, but most require the deposit of the data into an online data repository. First you must identify an appropriate repository for your data. Then you must prepare your data, including creating and assigning appropriate metadata and formatting your data, both according to best practices for your discipline and the particular repository.
Finding the right place – identifying a repository
There are literally hundreds of data repositories. It is a good idea to identify a repository for your data before you begin your research project. The University of Miami maintains the UM Scholarly Repository in which your data can be published and shared. Many other Data Repositories exist that may be appropriate as well.
Preparing your data
With a good Data Management Plan you will prepare your data for deposit as part of your research workflow. This includes creating and assigning appropriate metadata and formatting your data, both according to best practices for your discipline and the particular repository.
Navigating access options
When data is published or shared access rights range from open data that is freely available in the public domain to licensed data that has limited access rights and is served from proprietary publication platforms.
Digital Object Identifiers
A Digital Object Identifier (DOI) is a permanent online identifier for a digital asset; perhaps a journal article or a supplementary data set for a publication. As a part of research data services, the University of Miami can mint DOIs for your research products.
If you are working with sensitive data or personally identifiable information you need to take extra precautions to protect your research subjects and their information. Please see this list of resources if you think you are collecting information that requires privacy protection.
- What is Protected Health Information (PHI)?
- Protecting Sensitive Data is Everyone’s Responsibility
- Handling Sensitive Data FAQ
- UM Data Classification Policy
- NIST Guide to Protecting the Confidentiality of Personally Identifiable Information (PII)
- DHS Handbook for Safeguarding Sensitive Personally Identifiable Information
"One of the grand challenges of data-intensive science is to facilitate knowledge discovery by assisting humans and machines in their discovery of, access to, integration and analysis of, task-appropriate scientific data and their associated algorithms and workflows." - Force 11 FAIR Data Principles
Beginning in 2014 the Future of Research Communications and e-Scholarship (FORCE) working group is developing a set of principles for the dissemination of scientific data and other digital products that come from research; a set of best practices for data publishing. The FAIR acronym helps remind us of basic best practices, but please see their full set of guidelines at: https://www.force11.org/fairprinciples.
AAccessible Metadata and data available across open protocols
IInteroperable Data and metadata use standard or easily understood data structures
RReusable Metadata includes provenance and uses community accepted descriptions

Cameron Riopelle
- Director of Research Data & Open Scholarship
- criopelle@miami.edu
- (305) 284-1524
Thilani Samarakoon
- Biomedical Data Librarian
- thilani.samarakoon@miami.edu
- (305) 243-9126
Timothy Norris
- Data Scientist
- tnorris@miami.edu
- (305) 284-2826
Data Publication
DOIs, Data Publication, Sharing and Preservation Sensitive Data and Privacy Concerns FAIR DataDOI Services
DOI Services What is a DOI? DOI Minting GuidelinesData Repositories
Data Repositories The University of Miami Scholarly RepositoryData Licensing
Data Licensing Open DataData Publication Checklist
Data Publication Checklist Creating a Data PackageHow to get a DOI for your data or publication
The university of Miami provides DOI minting services through DataCite. We can help you publish your data in the University of Miami Institutional Repository and mint a DOI for the publication.
Please read our DOI minting guidelines and contact us if you would like DOIs for your digital assets.
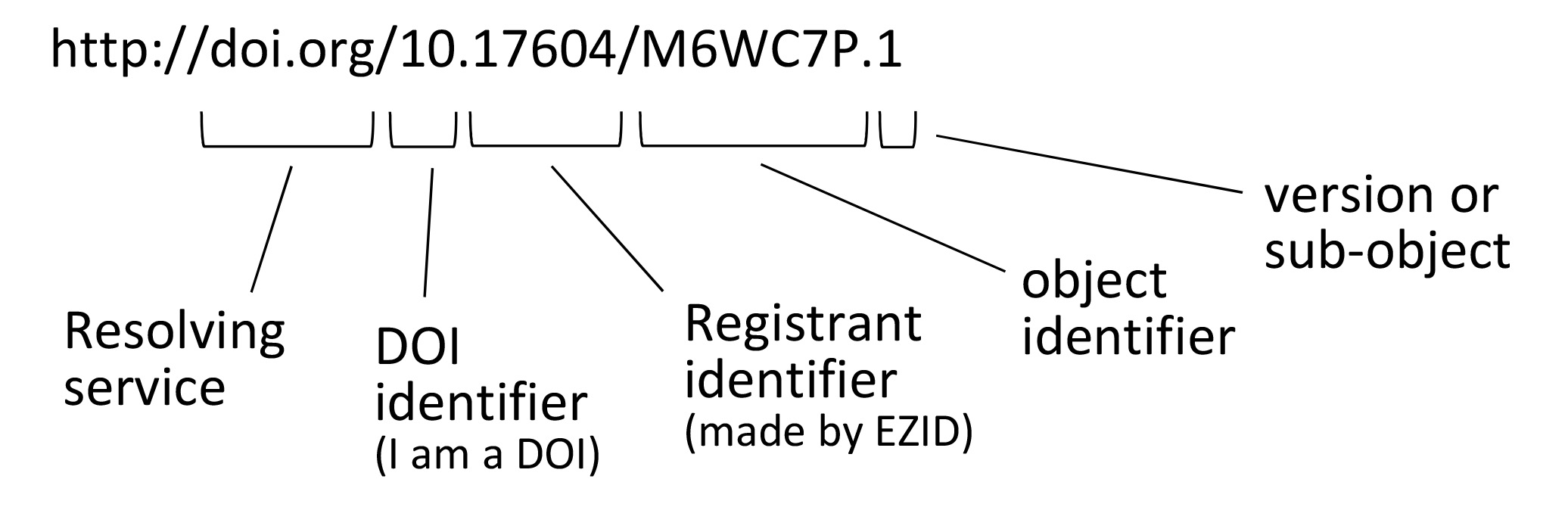
A Digital Object Identifier (DOI) is a permanent online identifier for a digital asset; perhaps a journal article or a supplementary data set for a publication.
The DOI is similar to a Uniform Resource Locator (URL) or a Uniform Resource Identifier (URI). All help to identify online resources.
What is special about the DOI, is that while the digital object may physically move from one server to another, the link will never break. This is guaranteed by the maintenance of database that links known assets to their physical locations. This service is provided as a partnership between the publisher of the digital asset and the DOI resolving service (e.g. https://doi.org/).
For more information see this history.
The anatomy of a DOI:
Some Definitions:
- DOI: Digital Object Identifier*
- ARK: Archival Resource Key*
- Object: a digital resource (can also be a collection of digital resources)
* Note that both the ARK and the DOI serve the same purpose.
- When you create the persistent identifier (DOI or ARK) three general requirements must be met:
- Data must be open –OR– licensed somehow. This means you want, and have the authority, to make the data available to the general public and the data will be considered a part of the public domain.
- The data is considered to be a part of the scholarly record (analogous to a journal article).
- You have the intention and ability to store and manage the object such that online access is maintained in perpetuity. This is your responsibility entirely.
- You are responsible to provide the minimum required metadata (description) for each object that you assign a DOI or ARK according to the DataCite Metadata Schema (see their latest release example for a simple dataset). YOU CANNOT MINT A DOI WITHOUT THIS MINIMUM REQUIREMENT.
- The metadata shall be in the public domain (can be used freely for discovery).
- [ best practice ] The data shall be presented on a landing page with links to the data, the metadata shown, links to any software needed for access, a suggested citation shown, and information on any access restrictions shown (if they exist).
- [ best practice ] If you are maintaining a repository, it should strive to be recognized with the Data Seal of Approval set of repository standards and the re3data repository listings.
- You cannot share the EZID login with a third party.
- You cannot place/store/archive objects on a third party server.
- All guidelines/terms here are subordinate to the UM institutional repository guidelines/terms.
Cameron Riopelle
- Director of Research Data & Open Scholarship
- criopelle@miami.edu
- (305) 284-1524
Thilani Samarakoon
- Biomedical Data Librarian
- thilani.samarakoon@miami.edu
- (305) 243-9126
Timothy Norris
- Data Scientist
- tnorris@miami.edu
- (305) 284-2826
Data Publication
DOIs, Data Publication, Sharing and Preservation Sensitive Data and Privacy Concerns FAIR DataDOI Services
DOI Services What is a DOI? DOI Minting GuidelinesData Repositories
Data Repositories The University of Miami Scholarly RepositoryData Licensing
Data Licensing Open DataData Publication Checklist
Data Publication Checklist Creating a Data PackageThere are thousands of data repositories that can serve as a permanent home for your data. Choosing the right one should be based on a simple decision tree, yet much like choosing a publishing venue before you write your article, the choice of repository is better made before you do your research.
All of the repositories mentioned below provide permanent identifiers (DOIs) as a way to better publicize your research results.
Do you want a discipline agnostic repository?
There are several good repositories that accept and publish data from all domains. These provide broad discovery and access services for your data.
- Harvard's instance of Dataverse accepts research data from any academic discipline.
- FigShare started as a way to share data behind published scientific figures and has grown to accept pretty much anything.
- ZENODO accepts data from any discipline as well as computer code hosted on github.
Is there a domain specific repository that suits your data well?
There are thousands of domain specific data repositories, some of which existed before the advent of digital data storage. The three below are very common, but there are many, many more (see the search tool at datacite).
- Dryad is a good repository for data in the life sciences
- ICPSR is a considered the standard for the social sciences
- ChemSpider is well known in chemistry
Would you like to search an index of all known repositories?
There is a well maintained registry of known research data repositories maintained by re3data and hosted at datacite.
Still don't know?
With so many choices choosing can be difficult. Contact us to make an appointment for a consultation. You might also consider depositing your data in the University of Miami Institutional Repository.
The UM scholarly repository is traditionally thought of as a place for dissertations, theses, and faculty scholarly output at the University of Miami, but our repository is also a home for research data.
Deposit your data
Through the University of Miami Libraries any faculty, staff, or student can deposit data into the scholarly repository.
This is not yet a self-service data repository and you must contact us to make a deposit request. We will do everything possible to help you prepare for and make the deposit.
By following best practices in research data management such as assigning appropriate metadata, choosing file formats suited for long term preservation, and preparing for ownership and privacy concerns, the deposit process will be streamlined.
Other alternatives?
While we will be happy to help deposit your data into the UM repository, perhaps a disciplinary repository will be a better home for your data.
Visit the repository help page or contact us for a consultation.
Cameron Riopelle
- Director of Research Data & Open Scholarship
- criopelle@miami.edu
- (305) 284-1524
Thilani Samarakoon
- Biomedical Data Librarian
- thilani.samarakoon@miami.edu
- (305) 243-9126
Timothy Norris
- Data Scientist
- tnorris@miami.edu
- (305) 284-2826
Data Publication
DOIs, Data Publication, Sharing and Preservation Sensitive Data and Privacy Concerns FAIR DataDOI Services
DOI Services What is a DOI? DOI Minting GuidelinesData Repositories
Data Repositories The University of Miami Scholarly RepositoryData Licensing
Data Licensing Open DataData Publication Checklist
Data Publication Checklist Creating a Data PackageCreative Commons Licenses
When you publish your data it is considered a best practice to license the data for use within the publication. Currently the most common license used for academic data publications is the creative commons international attribution 4.0 license; commonly known as the CC-BY 4.0 license (creative commons is a non-profit legal entity). Simply put, this means that another person or machine can re-use your data, modify it, and publish it again as long as they give attribution to you as the data creator. Note that the CC-BY license is not a copyright; it is not possible to copyright data in the United States.
The CC-BY license is not appropriate for all data publications. Creative commons includes other restrictions on use such as non-commercial or non-derivative. In the first case, the data cannot be used for commercial purposes and in the second the data cannot be modified and published in derivative works. You can see the full set of creative commons licenses at:
Open Data Commons Licenses
Apart from the creative commons licenses, another organization, the open data commons, publishes another set of licenses that may be more appropriate for highly curated data. You can see the full set of open data commons licenses at:
High Value Data
In cases of highly valuable data that require special restrictions for re-use, a custom data sharing agreement must be drafted and signed. The Office of Research maintains a set of guidelines for drafting such agreements. The Office of Privacy and Data Security at the Miller School of Medicine also provides a web form for requesting help with custom data sharing agreements.
Further Reading:
What is Open Data?
The term open data refers to a movement that recognizes the value of sharing (some) data in an increasingly data rich world. While there is a relation to the term open access in the academic publishing world, the two should not be confused. Furthermore, it is recognized that not everything should be 'open' or 'freely accessible'. Yet in certain cases, particularly with medical science and environmental data, the argument for open data is compelling indeed.
US Government Policy on Open Data
Many governments worldwide have adopted open data policies and the US government is not an exception.
- In 2003 the National Institute of Health (NIH) published data sharing requirements for all federally funded medical research with budgets greater than $500,000.
- In 2011 the National Science Foundation (NSF) adopted a data sharing policy.
- Also in 2011 the National Endowment for the Humanities (NEH) started to require Data Management Plans.
- In 2013 the Office of Science and Technology Policy issued a memo that mandates all federal agencies with more than $100M in R&D expenditures to "develop plans to make the published results of federally funded research freely available to the public within one year of publication and requiring researchers to better account for and manage the digital data resulting from federally funded scientific research." (Holdren 2013).
Agency Responses to the OSTP Memo
Many federal agencies now have plans in place and others are still working to comply with the OSTP memo. Several good lists of agencies, their responses to the memo, and their DMP requirements are maintained at the links below:
- SPARC maintains a current list of Federal Agency Requirements for Data Sharing and Article Publication.
- Funding Agency Guidelines - The University of Minnesota
- Research Funder Requirements - MIT
- OSTP Responses Facilitating Access to Federally Funded Research and Government Data - crowd sourced
Cameron Riopelle
- Director of Research Data & Open Scholarship
- criopelle@miami.edu
- (305) 284-1524
Thilani Samarakoon
- Biomedical Data Librarian
- thilani.samarakoon@miami.edu
- (305) 243-9126
Timothy Norris
- Data Scientist
- tnorris@miami.edu
- (305) 284-2826
Data Publication
DOIs, Data Publication, Sharing and Preservation Sensitive Data and Privacy Concerns FAIR DataDOI Services
DOI Services What is a DOI? DOI Minting GuidelinesData Repositories
Data Repositories The University of Miami Scholarly RepositoryData Licensing
Data Licensing Open DataData Publication Checklist
Data Publication Checklist Creating a Data Package- Get an ORCID!!
| The ORCID is like a drivers license for academic researchers. It is a way to make sure that you are identified as you, and not another author/researcher with your same name or initials. |  |
| Some journal publishers now require authors to have an ORCID to submit a manuscript. For publishing data, it is also considered a best practice to identify yourself with an ORCID. It takes a few minutes to register for an ORCID and connect it to the University of Miami at https://orcid.scholarship.miami.edu/. Make sure to use your UM email address to create the account. If you already have an ORCID, please also take a moment to connect it to the University of Miami. It is a simple process that starts here. If you want more information please see the ORCID@UM FAQ. |
|
- Write abstract for data publication (including several keywords).
- Identify all data creators, institutional affiliations, and contact information.
- Decide on the appropriate license for the data publication.
- Create metadata for the whole dataset as a README.txt file (authors, title, abstract, notes).
- Create metadata for any tabular data included (column headers, units, abbreviations)
- Confirm that a colleague in your discipline could reuse your data and descriptive metadata without your help.
- Confirm that you have all the correct permissions to distribute any data and/or code in the package.
- Transform all data files to formats identified as best practices within your discipline.
- Create data package as a single archive file (zip file, for example).
- How big is the data set (KB, MB, GB)?
- How many files are there?
- What kind of structure does the data have (excel files, relational database, text, pictures, audio, etc)?
- Do you have a good description of the data set (could someone in your field use the data set with your written description without contacting you)?
- Will you want to place the data set in the UM Scholarly Repository, or does it already have a "home" in a disciplinary repository?
- Are there any privacy concerns (personally identifiable data for human subjects)?
- What software do you need to view/open the data set?
- What will the value of this data be in five years? ten? fifty?
- What is your time frame?